技術文章
2021-02-09 AIGO計畫辦公室 5081
【AI解題案例】如何挑水果?自動辨識水果甜度方案
一、解題背景
很多人都有面對水果攤上一整籃水果,不知該如何挑到「好吃」的水果的經驗吧?本專案希望採用人工智慧技術來解決這個問題:只要用手機拍下眼前的蘋果,即可透過APP幫你分析這顆蘋果甜不甜,如何做到的呢?請看本文的剖析。

本專案的「出題方」為台灣楓康超市,他們遇到的問題是消費者在商場時,經常為挑選蘋果而不斷翻動眼前的一堆蘋果,導致某些蘋果彼此碰撞而損傷,希望有一套APP能協助買家挑選,降低水果被撞擊的機率。
接受挑戰的「解題方」是來自朝陽科技大學的「四葉草」團隊,該團隊成員已累積兩年以上的AI解題經驗,所擅長的領域包括影像辨識、CNN卷積神經網路,並具有資料集採集與建置、AI訓練環境架設及AI模型訓練的經驗。
二、解題架構:
以下來介紹他們的解題技術架構及執行方法:
AI模型訓練流程:

1. 準備訓練圖片
AI解題的第一個步驟自然是要取得可供訓練的資料集,也就是要辨識的「蘋果」資料集,包括蘋果的種類/產地、檢測日期、各角度照片、白利糖度值(Degrees
Brix, ° Bx)、口感說明等。其中蘋果的種類/產地可從其表面黏貼的標籤得知,其他資料就得靠自己來搜集,目前仍無法在網路上取得完全符合的資料集。
因此,該團隊為紐西蘭富士、智利富士和envy富士三種蘋果的「單顆」蘋果各拍攝了6個角度的相片,再一顆顆切片來做甜度測試。他們還做了「雙顆」蘋果拍攝:挑選一顆較為不紅的蘋果與一顆較紅的蘋果,做為比較的對照組,這麼一來便可以增加蘋果在進行辨識時的準確率。
除了「單顆」蘋果與「雙顆」蘋果的拍攝外,為了可以模擬消費者挑選蘋果的場景,也進行了「蘋果成堆」的照片六面拍攝。

圖說:「蘋果成堆」的六面拍攝
拍攝完蘋果的照片就進入蘋果甜度測試步驟。蘋果甜度檢測使用的是手持光學式白利糖度檢測器,此儀器的運作原理為利用光進入不同的介質時會造成行進路線的改變從而產生夾角,由此便能測出不同的液體甜度。為了取得完整的蘋果甜度資料,該團隊針對檢測甜度也設計了嚴謹的實驗流程。
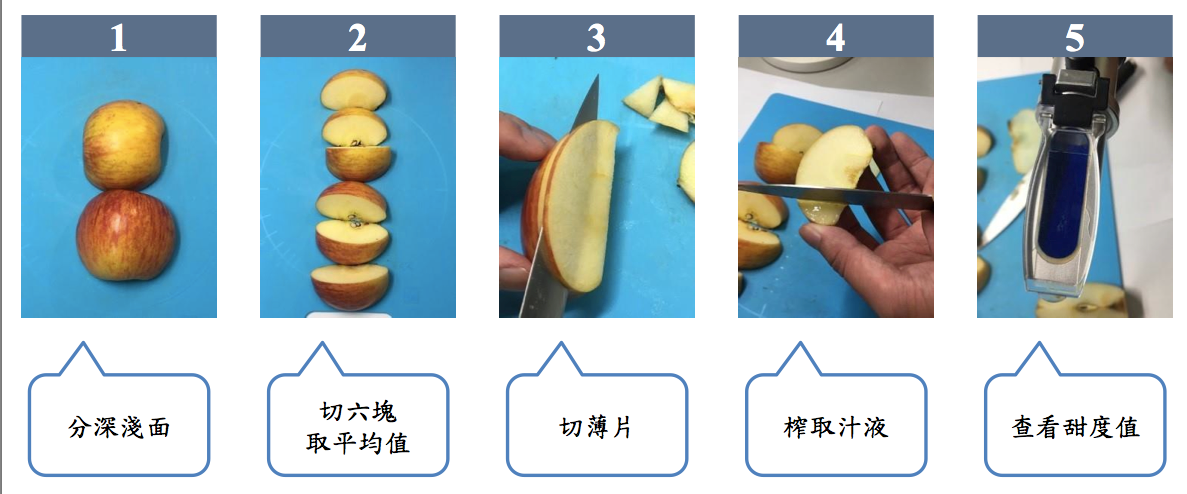
圖說:蘋果甜度值的檢測方式
最終得到的資料集包括 660 張的智利富士蘋果 (單顆)、330 張的智利富士蘋果(成堆)、660
張的紐西蘭富士蘋果(單顆)、330張的紐西蘭富士蘋果(成堆)、240張紐西蘭 envy富士蘋果(單顆)、120 張紐西蘭
envy富士蘋果(成堆)、300張雙顆蘋果照片、總共2640張照片,以及780 筆甜度資料,130 筆平均甜度資料。
2. 進行AI模型訓練
使用 AI 進行圖像辨識可以發現人類肉眼難以觀測出的細微特徵,進而判斷蘋果是否為甜。針對這專案的 AI
模型是使用圖像辨識能力較強的卷積神經網路,利用其特點即可達成高準確度的結果。
「四葉草」團隊使用的是留一交叉驗證法(leave-one-out
cross-validation),此方法僅保留一張圖片做測試,其餘的圖片則會全數用於訓練,完成訓練後會將正確的結果記錄為 1,錯誤的結果記錄為 0。
已完成的訓練的圖片會使用該團隊自行設計的自動化更換程式,將未測試的圖片從訓練的資料集內取出一張與已測試的圖片交換,往復訓練與圖片交換的流程,最終將正確結果的數量加總後,除以資料集的圖片總數即可得該模型的準確率。
本專案原先的訓練環境如下:
l 作業系統使用 Linux Ubuntu 16.04
l 使用運算速度較快的 GPU 替代 CPU 訓練,GPU 型號為 NVIDIA GeForce GTX 1050 Ti
l 程式語言使用支援多種套件的 Python
l 深度學習框架使用 TensorFlow
l 編譯器以 Spyder 與 Jupyter Notebook 為主
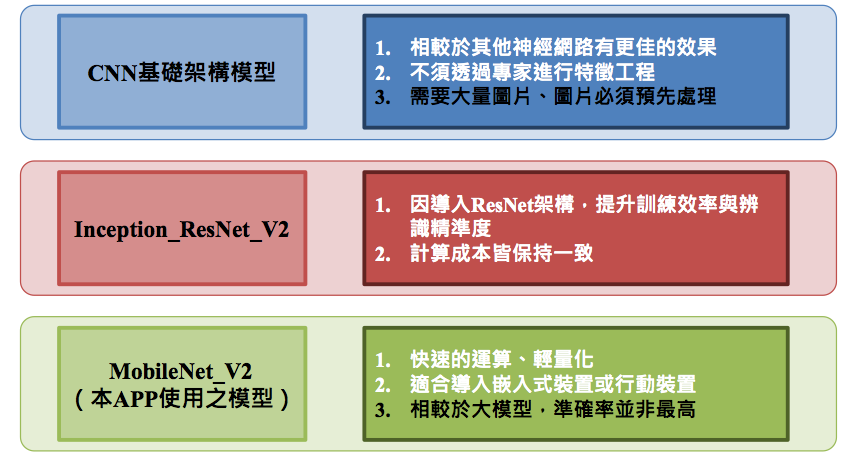
透過 AI 模型訓練,總共訓練了 3 種不同種類的模型,包括CNN
基本模型、Inception_RasNew_V2、MobileNet_V2。這3種模型中,CNN因架構較為簡單,適合剛入門的初學者;Inception_RasNew_V2不會因訓練的更深而降低準確率,有較佳的訓練性能;相較於傳統的卷積,MobileNet_V2能更快速地完成運算,效率也因此提升。3種模型的比較如下圖。
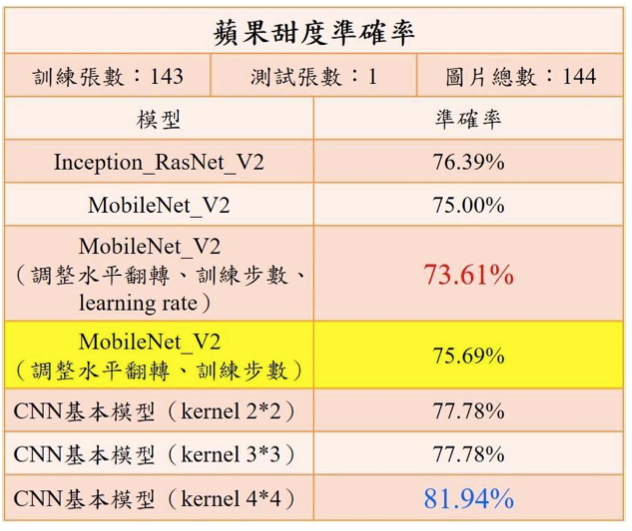
3種模型的實測結果中,以CNN 基本模型(使用 kernel4*)的 81.94%準確率最高,但最後為了在 APP 上 嵌入 AI 模型,為了避免
APP 的容量過於龐大,所以使用較為輕量的MobileNet_V2,準確率為 75.69%。請參考下表。
3. 產出模型與APP上架
手機已是大部分人生活中不可或缺的隨身裝置,其功能與效能也不斷提升,運用手機APP來辨識蘋果可以說是最方便的作法了。目前本專案不僅發展出用於辨識甜度的AI模型,也推出與楓康行動GO整合的APP,並已上架到Google
Play上了。
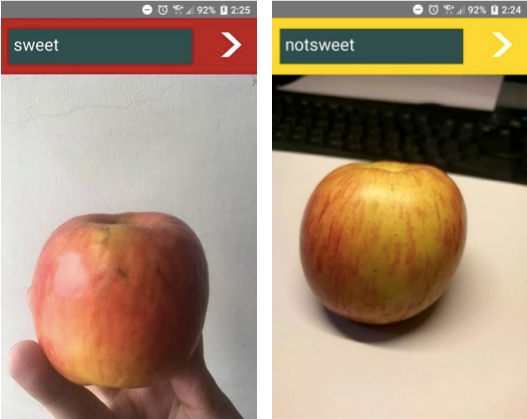
目前已成功能將訓練完成的模型內嵌於 APP中使用,模型經優化處理後已縮小至
17MB。此APP的甜度辨識功能會將甜度高於15以上判定為”sweet”,底色呈現紅色;若甜度低於 15
以下便被判定為”notsweet”,底色呈現黃色,如下圖。
三、創新亮點
本方案透過將訓練完成的 AI 模型嵌入至 APP
中,實現了即時的反饋結果,且具有無須網路即可達成應用目標。消費者只需使用手機內建的相機拍照,即可偵測出眼前蘋果的甜度,無須使用一般極昂貴的甜度分析儀器,才能像有經驗的果農或水果商一樣挑出好吃的水果,相當實用。
四、結論
本方案在開發過程中確實遇到不少困難,特別是在採集資料上,例如蘋果的拍攝角度、模擬超市的燈光環境、甜度的測試等等。在上述的幾點困難點中,最困難的就是照片的拍攝參數設定,因為並非每支手機的解析度、RGB
等都相同,所以拍出來的照片也皆不相同,只能從組員中挑選一支手機當作拍攝手機,以達到標準性。
因此,在本次解題中若有要改善的項目,可能就是在採集資料上的時間過長,但為了使訓練時的資料是可行的,所以才會在這個環節比較謹慎、重複測試不同的方法。總體而言,本方案以下4個好處:1.
減少消費者翻攪行為;2. 提升企業與消費者之間的互動體驗:3. 降低企業營運成本;4. 減少資源的浪費。

展望未來,這套方法除了用於超市,也可應用於智慧農業與品質監控:在智慧農業上,可以透過無人機來進行蘋果的監測,當蘋果的甜度達到一定數值時,即可進行採收蘋果的動作;在品質監控上,可以透過甜度將蘋果進行品質分級,進一步還可應用於電商平台作為蘋果品質保證的依據,舉例來說,消費者在電商平台購買蘋果時,可透過掃描電商平台上圖片結果,來判斷是否要購買此蘋果,店家亦可透過本研究來證明其蘋果品質。
延伸閱讀: