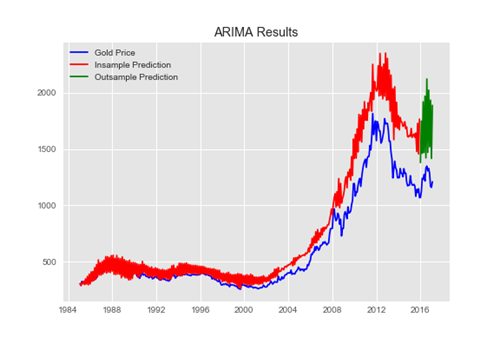
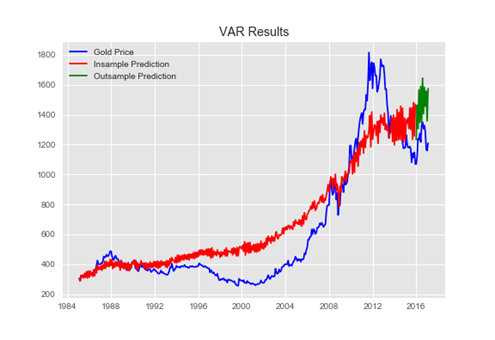
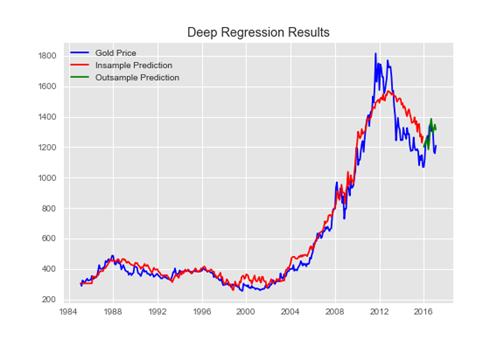
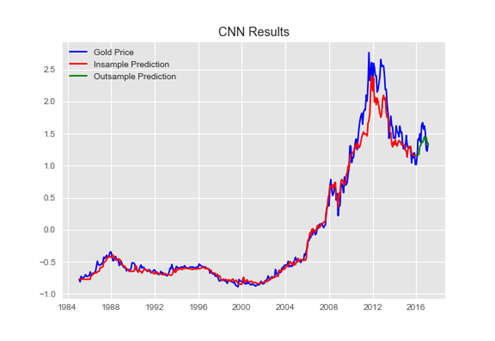
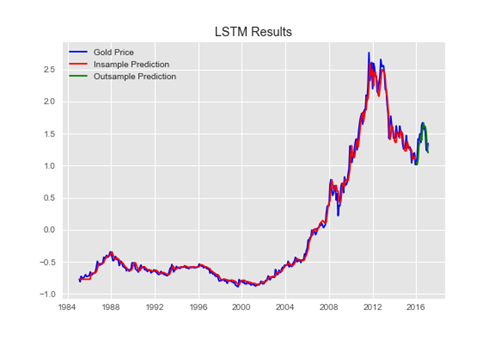
其實這方面, 自幹是不難, 套回老話一句還是資料要夠、要對! 像是網路上之前就有人試過針對英鎊對美金的收盤價, 進行收集以後用ARIMA分析其趨勢, 實作起來倒是不難! 範例資料可以在這裡下載 ==> https://drive.google.com/open?id=1Z32dAwTW2wkAskskwKLelzK7qzip7XhY
我是拿Python3開發的, 不過特別注意的是安裝的套件要有pandas、matplotlib、statsmodels
大家可以試試看 :
from pandas import read_csv
from matplotlib import pyplot
from statsmodels.tsa.arima_model import ARIMA
def GetData(fileName):
return read_csv(fileName, header=0, parse_dates=[0], index_col=0).values
def StartARIMAForecasting(Actual, P, D, Q):
model = ARIMA(Actual, order=(P, D, Q))
model_fit = model.fit(disp=0)
predicti />
return prediction
ActualData = GetData('exchange.csv')
NumberOfElements = len(ActualData)
TrainingSize = int(NumberOfElements * 0.7)
TrainingData = ActualData[0:TrainingSize]
TestData = ActualData[TrainingSize:NumberOfElements]
Actual = [x for x in TrainingData]
Predicti>
for timepoint in range(len(TestData)):
ActualValue = TestData[timepoint]
Predicti 3,1,0)
print('Actual=%f, Predicted=%f' % (ActualValue, Prediction))
Predictions.append(Prediction)
Actual.append(ActualValue)
pyplot.plot(TestData)
pyplot.plot(Predictions, color='red')
pyplot.show()
結果應該可以看到, 原始資料與預測的線段還蠻貼近的, 關鍵在於 TrainingSize = int(NumberOfElements * 0.7) 這一列, 這列表示會把原始資料中的70%拿來做訓練, 剩餘的30%當作測試資料, 調整看看, 原始資料與預測的線段是否會因此開始略有不同?
.......
Actual=66.328000, Predicted=67.659417
Actual=64.740000, Predicted=67.057834
Actual=62.450000, Predicted=65.268602
Actual=64.348000, Predicted=63.473869
Actual=65.430000, Predicted=64.260047
Actual=62.711000, Predicted=64.671368
Actual=62.663000, Predicted=63.293874
Actual=62.520000, Predicted=63.267024
Actual=61.780000, Predicted=62.550437
Actual=59.665000, Predicted=62.024397
Actual=57.167000, Predicted=60.451596
Actual=56.001000, Predicted=58.364315
Actual=57.585000, Predicted=56.873684
Actual=57.820000, Predicted=57.339436
Actual=57.090000, Predicted=57.387769
Actual=58.910000, Predicted=57.256028
Actual=59.520000, Predicted=58.513376
Actual=61.223000, Predicted=58.926507
Actual=62.147000, Predicted=60.578724
Actual=61.660000, Predicted=61.492646
Actual=59.988000, Predicted=61.605069
Actual=61.067000, Predicted=60.591967
Actual=61.540000, Predicted=61.095288
Actual=63.660000, Predicted=61.144890
Actual=62.740000, Predicted=62.917183
Actual=60.080000, Predicted=62.548462
Actual=60.552000, Predicted=61.081593
Actual=61.542000, Predicted=60.975584
Actual=61.698000, Predicted=61.118603
Actual=60.870000, Predicted=61.428925
Actual=59.610000, Predicted=61.080842
Actual=58.670000, Predicted=60.160284
Actual=59.730000, Predicted=59.212750
Actual=59.795000, Predicted=59.600040
Actual=61.550000, Predicted=59.529964
Actual=62.070000, Predicted=61.004988
Actual=61.652000, Predicted=61.522841
Actual=61.686000, Predicted=61.664595
Actual=58.795000, Predicted=61.760668
Actual=58.908000, Predicted=59.644325
Actual=56.210000, Predicted=59.494302
Actual=54.917000, Predicted=56.970193
Actual=52.488000, Predicted=55.882759
Actual=52.770000, Predicted=53.473277
.......