技術文章
2021-06-01 AIGO計畫辦公室 4547
提升深度學習算力與解釋力為未來開發重點
人工智慧從1980年末機器學習的發展略分為淺層學習(Shallow Learning)與深度學習(Deep
Learning)兩大學習趨勢。2016年3月Google
DeepMind開發的AlphaGo以四比一的勝率擊敗南韓棋王李世乭,AlphaGo使用的深度學習技術隨即引起各界關注。自此,深度學習成為近年人工智慧的重大推進角色,替AI帶來了革命性的突破。
深度學習是以人工神經網路為架構的一種演算法,又稱「深度神經網路」(Deep Neural Networks,
DNN),以模擬生物神經元(Neuron)的運作方式,讓機器能具備自我學習力。DNN具備多層的神經網路,在輸入層(Input
Layer)與輸出層(Hidden Layer)的中間至少具備一個以上的隱藏層(Hidden
Layer),能夠分析複雜與高維度的資料,解讀出巨量資料中所涵蓋的豐富資訊,並對未來做出更精準的解釋、分析與預測。
深度學習雖展現了強大的結果與預測能力,但也面臨了以下課題:(一)模型建立困難:DNN的高複雜性,需仰賴多位AI專家建構;(二)模型運行困難:深度學習需要大量的算力支持,模型運行費力,為了提高算力企業需配備高規格的硬體設備(如:GPU與設備環境等)相對付出的金錢成本也高;(三)模型難以解釋:深度學習的解釋力不佳,歸因於DNN涵蓋許多隱藏層,如同黑盒子般,難以了解它的決策依據。鑑於上述深度學習面臨的挑戰,建構可解釋的AI以及提升AI速度減輕運算負擔將是未來AI模型的開發重點趨勢。
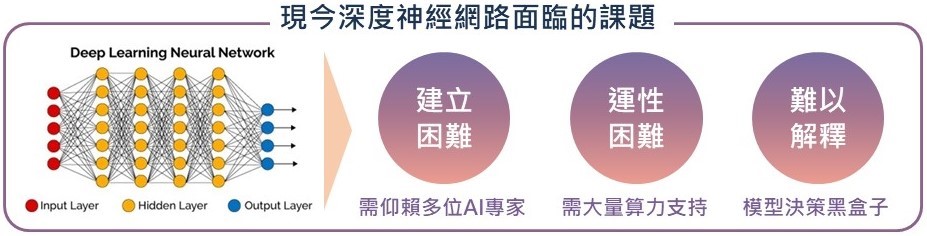
資料來源:MIC,2021年5月 圖1 現今深度神經網路面臨課題
Darwin AI專利生成技術讓模型更輕巧且運行更快
新創公司Darwin AI 2017年成立於加拿大,致力於深度學習演算法設計、模型最佳化和可解釋性。創辦人兼技術長 Alexander
Wong在攻讀加拿大滑鐵盧大學系統工程博士學位時,他的博士論文是關於電腦視覺研究,但是實驗室沒有那麼多的資金去添購所需要的硬體設備,因此他發明了可以讓深度神經網路模型更小、速度更快的生成合成技術(Generative
Synthesis),而這項技術變成為開創Darwin AI的核心技術。
2019年5月Darwin
AI獲得Frost&Sullivan頒布的技術創新獎;同年10月被選為「Gartner企業AI治理與道德回應的優秀廠商」;2020年先後入選CB
Insights AI 100以及CB Insights Game Changer,將其列為透明可解釋性AI平台遊戲顛覆者。多項殊榮確立了Darwin
AI在前瞻技術的代表性,替人工智慧開發下一代技術的潛力新創。
生成合成技術大幅精簡模型尺寸並保持準確度
Darwin
AI的核心產品為基於生成合成技術的「Gensynth」平台,它能夠讓原本複雜的深度學習神經網路模型減小尺寸、降低複雜度、執行速度更快並且讓AI決策能夠被解釋的AI模型。過去建構深度神經網路學習機制,模型開發週期需要耗費數週至數月的開發時間,才能夠產出決策驗證模型,Gensynth
可在數日之內根據用戶定義與需求生成最佳化模型,以AI建構AI實現加速深度學習開發週期的目標。
Darwin
AI四大創新之處分述如下:(一)提升AI性能:大幅度地精簡深度神經網路尺寸與降低複雜度,減少運算需求的深度學習解決方案;(二)保持模型準確度:在精簡深度神經網路的同時依然保持模型準確度並降低推理時間;(三)模型可解釋性:Gensynth可以解讀神經網路「層」或神經「元」詳細的資訊,可以促使深度學習模型具備可解釋性,以了解AI決策;(四)多元化部署方式:提供多元化的平台部署,讓高度最佳化的深度神經網路,可部署在雲端運算或頻寬有限的邊緣場景。
透過生成、更新到解讀三階段來回調整模型以達最佳化
Darwin
AI的核心技術為生成合成技術,此技術使用AI在訓練過程中觀察神經網路,從而對需理解的神經網路進行深入的數學理解,平台運作涵蓋四個過程,第一是生成(Generate),意思是系統開發人員放入了一個DNN模型到平台上,平台會開始自動生成一個最佳化的模型,其中會經過更新(Update)持續的更新模型使其能夠符合最佳化,再經過解讀(Inquire)後模型判別者了解該模型是否達到最佳化,譬如是否符合在邊緣的算力與速度需求。從生成、更新到解讀三階段可能經過數次的來回調整的循環過程,直到最終產出最佳化模型。
Gensynth使用TensorFlow機器學習框架,提供基於網頁的排版介面,以Docker虛擬容器託管在客戶端環境中。Gensynth提供直觀的使用者介面讓神經網路可視化,系統開發人員可以在生成、更新和解讀過程中,更深入的了解模型的內部運作及如何達到最佳化,以提高調適效率和準確度。
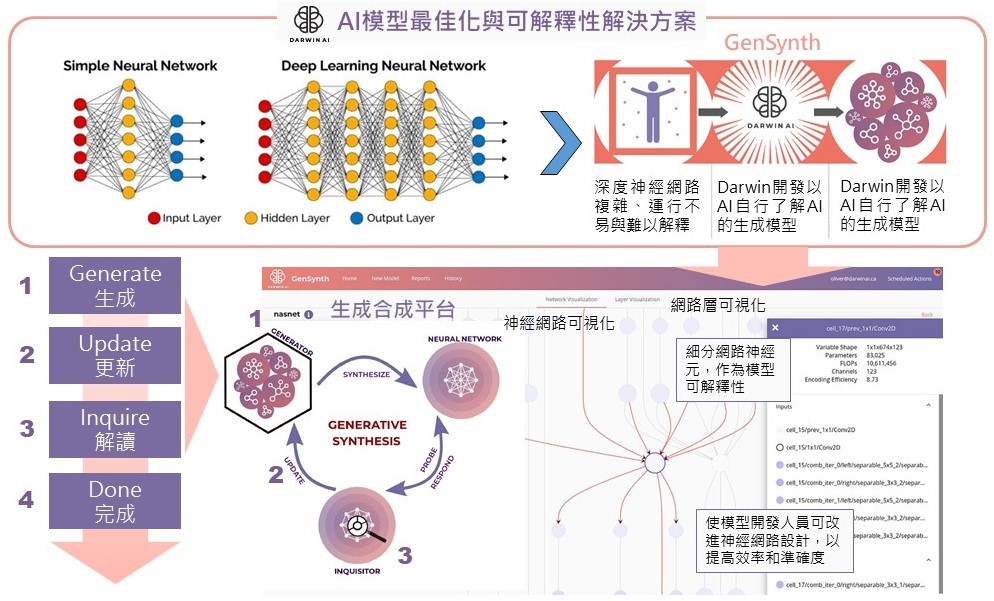
資料來源:Darwin AI,MIC整理,2021年5月 圖2 Gensynth生成合成平台
GenSynth提升Audi自駕車圖像辨識3.8倍速度
2019年與Audi自駕車開啟個案研究合作,Audi使用GenSynth平台來加速自動駕駛物體偵測的量身設計,以最佳化深度神經網路的速度。在自駕車領域的挑戰之一,在於模型的物體辨識、偵測和反應速度,如果能提升它的DNN效能,除了可以提升推論能力與速度同時也可以降低耗能,將計算資源分給其他任務。經研究報告指出,GenSynth成功縮小Audi深度學習模型90%,協助Audi開發人員將訓練模型的速度加快了4倍,並且將GPU的處理時間縮減四分之三,提升模型3.8倍的辨識速度並保持了準確性。
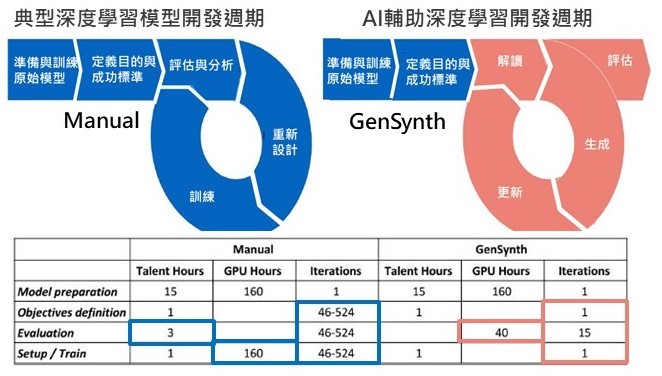
資料來源:Darwin AI、Audi,MIC整理,2021年6月 圖3 GenSynth與Audi傳統開發週期比較
以AI建構AI 開啟下一代人工智慧新技術
在萬物聯網時代下,企業嘗試在邊緣端作業,從工廠廠區、商店、城市街道到緊急救護設施,來自數十億個物聯網感測器的資料,在邊緣端由邊緣伺服器進行處理,使其在必要時加快即時決策的速度。深度神經網路構建複雜在運行上需大量算力支持,在基於邊緣運算的自駕車系統或是移動設備等場景中,能占用的計算資源和能耗都十分有限。深度學習巨大的潛力往往會被架構困難度與運算複雜度抵銷,使其難以廣泛地部署在邊緣。
Darwin AI已獲得專利的生成合成技術致力於解決這些痛點,GenSynth平台開發人員能夠產出精簡的深度神經網路,使用AWS 和Microsoft
Azure上的 Nvidia
GPU,加上部署於本地的系統來加快開發週期,讓開發人員可以在更短時間內來擴展出多個神經網路,該技術能協助企業高效率開發深度學習模型、縮小模型尺寸、降低模型複雜度並且保持模型的準確度並減少推理時間。此外,GenSynth平台促進深度學習模型的可解釋性,這在現今需要符合AI監管的產業至關重要。Darwin
AI協助企業能夠以更快、更強大的方式開發深度學習模型,從而縮短了產品上市時間,以AI建構AI開啟下一代的人工智慧新技術。

財團法人資訊工業策進會 產業情報研究所(MIC)
張皓甯 產業分析師